In this tutorial, we’re going to learn how to calculate streaks in Python using the pandas library and visualize them using Matplotlib.
A streak is when several events happen in a row consecutively. In this post, we’re going to be working with NBA shot data and looking at players who made or missed a number of shots in a row. That said, streaks can take many forms. You can just as easily use this technique to detect and measure other streaks like consecutive days logging in to an app or website.
This tutorial assumes you have some basic familiarity with the pandas and Matplotlib libraries.
Part One: Detecting and Calculating Streaks
We’ll start by learning how to calculate streaks using test data. Let’s import NumPy and pandas and get started.
import pandas as pd
import numpy as np
Creating Test Streak Data
The test data will help us develop a system for calculating streaks. We’ll:
- set a random seed using
np.random.seed()to give us reproducible results. - use
np.random.choice()to generate an array ofmakeandmissstrings. - convert that array to a column in a pandas dataframe.
np.random.seed(23)
seq = np.random.choice(['make', 'miss'], size=10, p=[.65, .35])
streaks = pd.Series(seq, name='result').to_frame()
streaks
If you look at this column, you’ll notice several streaks of makes and misses, ranging from one to four in length. The diagram below illustrates the streaks:

Identifying the Start of Each Streak
The first step in calculating our streak in pandas is to identify the start of each streak. We’ll do this by using Series.shift() to create a new series with each row shifted down one position. We’ll then use Series.ne() to compare the two series' and tell us which are not equal.
Before we look at the code for this, let’s take a moment to visualize the comparison:

Notice how every row containing True corresponds with the start of a streak as indicated by our first diagram.
Let’s look at the code version of this. We’ll create a new column, start_of_streak that shows us which rows are the start of a new streak:
streaks['start_of_streak'] = streaks.result.ne(streaks['result'].shift())
streaks
Creating Streak IDs
Next, we want to create a unique ID for each streak. Let’s look at what we’re aiming for, and then we’ll discuss how to get there:

To calculate this column, we’re going to use Series.cumsum() to calculate the cumulative sum of our start_of_streak column. The cumsum() method is going to treat True as 1 and False as 0, which has the effect of incrementing the count for every True value, which indicates the start of each streak, which you can see illustrated below:

Let’s look at this in code:
streaks['streak_id'] = streaks['start_of_streak'].cumsum()
streaks
Now we have a unique identifier for each of our streaks. Our last task is going to be to create our streak count!
Counting Streaks
We’re going to group by our streak_id and then use GroupBy.cumcount() to count each streak. This can be a bit hard to visualize using numbers, so let’s look at an example using a ‘toy’ series containing strings of colors:

Notice that cumcount() starts counting from zero, so we’ll have to add one to the result that we get.
Now we understand how this works, let’s look at how it will work with our shot streak data:

Let’s proceed with our final calculation.
streaks['streak_counter'] = streaks.groupby('streak_id').cumcount() + 1
streaks
Creating a Streak Function
We’re going to be calculating streaks a lot, so let’s create a function that uses the logic we’ve just outlined. Our function will take a dataframe with a results column containing make and miss data and return that same dataframe with an added streak_counter column.
The format of the make/miss data actually doesn’t matter as long as they are unique - it could be make and miss strings as in our example above, Y and N strings, or True or False values. Because we start by shifting and comparing the values, as long as they’re unique it will work.
def generate_streak_info(shots):
"""
Parameters
----------
shots:
A dataframe containing data about shots.
Must contain a `results` column with two
unique values for made and missed shots.
Must be homogenous (contain only shots
that qualify for the streak type you want
to calculate (eg all FT for a single
player) and be pre-sorted by time.
Returns
-------
shots_with_streaks:
The original dataframe with a new column
`streak_counter` containing integers with
counts for each streak.
"""
data = shots['result'].to_frame()
data['start_of_streak'] = data['result'].ne(data['result'].shift())
data['streak_id'] = data.start_of_streak.cumsum()
data['streak_counter'] = data.groupby('streak_id').cumcount() + 1
shots_with_streaks = pd.concat([shots, data['streak_counter']], axis=1)
return shots_with_streaks
shots = streaks['result'].to_frame()
generate_streak_info(shots)
Now we’ve created our function, let’s apply it to some real-world data.
Our NBA Playoffs Shot Data
We’ll be working with a CSV dataset containing shot data from the 2018 NBA playoffs. This playoff year had some interesting shooting streaks which makes it great for our analysis.
The data was originally sourced using the NBA stats API and has been cleaned and prepared for our use. You can download this dataset here.
Let’s start by reading in the data and examining the first few rows:
shot_data = pd.read_csv("playoff_shots.csv")
shot_data.head()
shot_data['shot_type'].value_counts()
Each row in the dataset represents a shot attempt from the 2018 playoffs in chronological order. The dataset contains the following columns:
game_id: The NBA’s unique identifier for each game.game_code: The game code, which includes the date and the abbreviations of each team.game_description: The description of the game — the home team, away team, and series game number.period: The period in which the shot attempt was made.period_time: The time in the period that the shot attempt was made.player_name: The name of the player who attempted the shot.player_id: The NBA’s unique id for the player who attempted the shot.team: The team of the player that took the shot.shot_type: The shot type — either2PT,3PTorFT.result: The result of the shot — eithermakeormiss.
The function we created to calculates streaks needs homogenous data - that is, data for a specific player and shot type. To make this easier, let’s create a function which will filter shots:
def filter_shots(player, shot_type):
"""
returns shot data for a single player and shot type
Parameters
----------
player:
A string containing a player name to be
filtered.
shot_type:
The shot type. One of '3PT', '2PT', 'FT'
Returns
-------
player_shots:
A filtered dataframe of shot data.
"""
# filter the data
filt = (shot_data['player_name'] == player) & (shot_data['shot_type'] == shot_type)
player_shots = shot_data[filt]
player_shots = player_shots.reset_index(drop=True)
# check that the player has some shot data
if not player_shots.shape[0]:
raise ValueError(f"Player '{player}' has no shots of type '{shot_type}'.")
return player_shots
Let’s use our function to produce a dataframe of Kevin Durant’s freethrows.
durant_ft = filter_shots("Kevin Durant", "FT")
print(durant_ft.shape)
durant_ft.head(10)
Kevin Durant took 152 freethrows across the playoffs, and made his first nine shots in a row.
Calculating Kevin Durant’s Freethrow Streaks
Let’s now use our generate_streak_info() function we created earlier to calculate Kevin Durant’s freethrow streaks:
durant_ft_10 = generate_streak_info(durant_ft).head(10)
durant_ft_10
You’ll notice that there’s a new column added to the end of the dataframe with streak data.
Part Two: Analyzing Streaks
The next section of the tutorial deals with analyzing the streak data that we’ve created.
Creating Streak Summaries
Kevin Durant shot 152 freethrows in the 2018 playoffs, so it’s going to be hard for us to understand his streaks by looking at one big dataframe. One option is to create a dataframe that contains a row for each streak that summarizes his shooting data.
Let’s use the first 10 rows of Kevin Durant’s data to understand the technique that we’ll use.
cols = ["game_description", "shot_type", "result", "streak_counter"]
durant_ft_test = durant_ft_10[cols].copy()
durant_ft_test
Our strategy is going to be to collect data from the first row of the streak and the last row of the streak and combine them.

We’ll start by creating a boolean column identifying the start of each streak by identifying the rows where streak_counter is equal to one:

Let’s look at the code version of that
durant_ft_test['start_of_streak'] = durant_ft_test['streak_counter'] == 1
durant_ft_test
If we shift that boolean column up one position (and fill the last value with true), we get a boolean column for the end of each streak.

Let’s create that new column.
durant_ft_test['end_of_streak'] = durant_ft_test['start_of_streak'].shift(-1, fill_value=True)
durant_ft_test
Let’s use the start column as a filter and move the start game_description value to a new column.

We’ll use DataFrame.loc[] to combine the boolean filter while adding a new column:
durant_ft_test.loc[durant_ft_test['start_of_streak'], 'start_game'] = durant_ft_test['game_description']
durant_ft_test
Next, we’ll fill those values downwards into the ‘empty’ (NaN) cells.

To do this, we’ll use Series.fillna() with the ffill (forward fill) option.
durant_ft_test['start_game'] = durant_ft_test['start_game'].fillna(method="ffill")
durant_ft_test
Now if we look at the final row of each streak, we have all the information we need:

Let’s filter to just those rows and rearrange the columns to give us a summary:
durant_ft_test = durant_ft_test[durant_ft_test['end_of_streak']]
durant_ft_test = durant_ft_test.rename({
"game_description": "end_game",
"streak_counter": "streak_length",
"result": "streak_type"
}, axis=1)
cols = ["shot_type", "streak_type", "streak_length", "start_game", "end_game"]
durant_ft_test = durant_ft_test[cols]
durant_ft_test
Creating a Streak Summary Function
Let’s create a function that follows the same logic. As well as the game description we’ll also calculate the period and time that the streak started and ended.
def streak_summary(shots):
"""
Parameters
----------
shots:
A DataFrame containing data about
shots. Must be homogenous (contain
only shots that qualify for the streak type
you want to calculate, eg all FT for a single
player) and pre-sorted.
Must contain the following columns:
player_name:
The name of the player
shot_type:
The type of shot taken.
result:
Containing two unique values for made
and missed shots.
game_description:
A descriptor of the game in which each
shot occured.
period:
The period in which each shot occured.
period_time:
The time remaining in the period when
each shot occured.
Returns
-------
summary:
A DataFrame summarizing the shooting streaks,
containing the columns: `player_name`,
`shot_type`, `streak_type`, `streak_length`,
`start_game_description`, `start_period`,
`start_period_time`, `end_game_description`,
`end_period`, and `end_period_time`.
"""
# calculate raw streak data
summary = generate_streak_info(shots)
# streak summary info
summary["streak_type"] = summary["result"]
summary["streak_length"] = summary["streak_counter"]
# streak start info
start_filter = summary['streak_counter'] == 1
start_target_cols = ["start_game_description", "start_period", "start_period_time"]
source_cols = ["game_description", "period", "period_time"]
for target, source in zip(start_target_cols, source_cols):
summary.loc[start_filter, target] = summary[source].astype(str)
summary[target] = summary[target].fillna(method="ffill")
# streak end info
end_target_cols = ["end_game_description", "end_period","end_period_time"]
for target, source in zip(end_target_cols, source_cols):
summary[target] = summary[source].astype(str)
# tidy up and filter data
all_cols = ["player_name", "shot_type", "streak_type",
"streak_length"] + start_target_cols + end_target_cols
end_filter = start_filter.shift(-1).fillna(True)
summary = summary.loc[end_filter, all_cols].reset_index(drop=True)
return summary
Let’s use our function to summarize Kevin Durant’s freethrow streaks across the whole 2018 playoffs:
streak_summary(durant_ft)
Durant had 5 double-digit make streaks, including 41 made shots in a row that stretched across two series'!
Finding the longest streaks
To find the longest streaks we would need to summarize the shots of each player, for each shot type. There are two approaches we could take here:
- Loop over each player and shot type and use our function to create summary dataframes for each. We could then combine the summary dataframes into one master dataframe and analyze the data.
- We could sort our source dataframe by player and shot type so that each players streaks are together, update our function to take the shot type and player name into account when grouping, and use the function once.
The second option is a better option, as it allows us to use pandas vectorization and avoid loops which are slower and more cumbersome.
Let’s start by sorting our dataframe.
sort_order = ["player_id", "shot_type", "game_id", "period", "period_time"]
ascending = [True, True, True, True, False]
shot_data_sorted = shot_data.sort_values(sort_order, ascending=ascending)
Next, let’s create a generate_streak_info_all() function, based on generate_streak_info(), to process the streaks for all players.
Here’s how our function differs from the original:
- Instead of just extracting the
resultcolumn from the original dataframe, we’ll also include theplayer_idandshot_type. - At the group by stage, we’ll group by these two new columns, as well as the
streak_id.
These changes help us avoid the case where the dataframe has two shots in a row with an identical result that are either a different shot type or different player.
def generate_streak_info_all(shots):
"""
Parameters
----------
shots:
A dataframe containing data about shots.
Must contain a `results` column with two
unique values for made and missed shots.
The dataframe must also have a
`player_id` column which uniquely
identifies each player and a `shot_type`
column that identifies each distinct shot
type.
Returns
-------
shots_with_streaks:
The original dataframe with a new column
`streak_counter` containing integers with
counts for each streak.
"""
data = shots[['player_id', 'shot_type', 'result']].copy()
data['start_of_streak'] = data['result'].ne(data['result'].shift())
data['streak_id'] = data.start_of_streak.cumsum()
data['streak_counter'] = data.groupby(['player_id',
'shot_type',
'streak_id']).cumcount() + 1
shots_with_streaks = pd.concat([shots, data['streak_counter']], axis=1)
return shots_with_streaks
Next, we’ll update streak_summary(), creating a streak_summary_all() function.
The only difference between this and our original is that it will call the updated generate_streak_info_all() function instead of generate_streak_info().
def streak_summary_all(shots):
"""
Parameters
----------
shots:
A DataFrame containing data about
shots. Must be pre-sorted by player,
shot type, and time.
Must contain the following columns:
player_id:
A unique identifier for each player.
player_name:
The name of the player
shot_type:
The type of shot taken.
result:
Containing two unique values for made
and missed shots.
game_description:
A descriptor of the game in which each
shot occured.
period:
The period in which each shot occured.
period_time:
The time remaining in the period when
each shot occured.
Returns
-------
summary:
A DataFrame summarizing the shooting streaks,
containing the columns: `player_name`,
`shot_type`, `streak_type`, `streak_length`,
`start_game_description`, `start_period`,
`start_period_time`, `end_game_description`,
`end_period`, and `end_period_time`.
"""
# calculate raw streak data
summary = generate_streak_info_all(shots)
# streak summary info
summary["streak_type"] = summary["result"]
summary["streak_length"] = summary["streak_counter"]
# streak start info
start_filter = summary['streak_counter'] == 1
start_target_cols = ["start_game_description", "start_period", "start_period_time"]
source_cols = ["game_description", "period", "period_time"]
for target, source in zip(start_target_cols, source_cols):
summary.loc[start_filter, target] = summary[source].astype(str)
summary[target] = summary[target].fillna(method="ffill")
# streak end info
end_target_cols = ["end_game_description", "end_period","end_period_time"]
for target, source in zip(end_target_cols, source_cols):
summary[target] = summary[source].astype(str)
# tidy up and filter data
all_cols = ["player_name", "shot_type", "streak_type",
"streak_length"] + start_target_cols + end_target_cols
end_filter = start_filter.shift(-1).fillna(True)
summary = summary.loc[end_filter, all_cols].reset_index(drop=True)
return summary
Now we’ve prepared our function, let’s create a summary for all players:
summary_all_players = streak_summary_all(shot_data_sorted)
summary_all_players.head(10)
Now that we have a summary of every player’s streaks, let’s find some of the biggest make and miss streaks over the playoffs.
We’ll use Python’s itertools.product() to iterate over each permutation of shot and streak type. Then, we’ll use DataFrame.nlargest() to find the longest streaks for each permutation.
import itertools
shot_types = ["2PT", "3PT", "FT"]
streak_types = ["make", "miss"]
for shot_type, streak_type in itertools.product(shot_types, streak_types):
# filter for the shot and streak type
filt = ((summary_all_players["shot_type"] == shot_type)
& (summary_all_players["streak_type"] == streak_type)
)
filtered_summaries = summary_all_players[filt]
# find the top 5 values
top_5 = filtered_summaries.nlargest(5, "streak_length")
# print a summary
print_columns = ["player_name", "streak_length"]
print(f"\n----- Largest {streak_type} streaks for {shot_type} -----\n")
print(top_5[print_columns].reset_index(drop=True))
print()
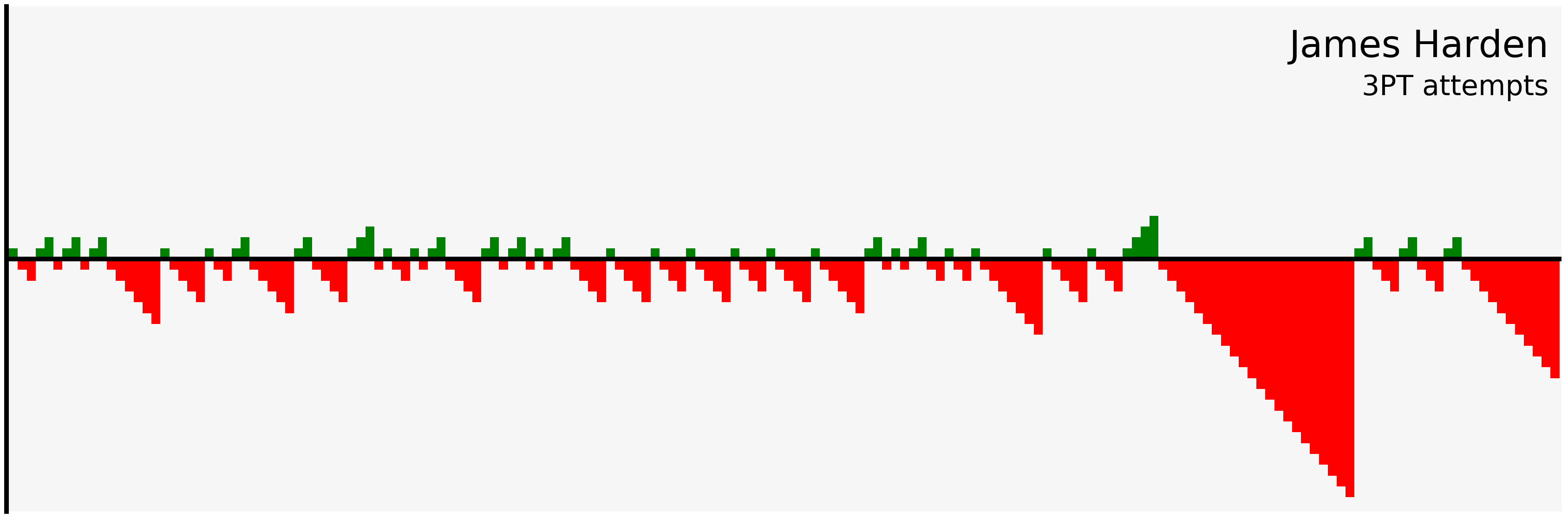
There are some interesting streaks here, including James Harden missing 22 three-pointers in a row! In the final section of the tutorial we’ll visualize some of these streaks.
Part Three: Visualizing Streaks
The summaries we created in the previous section help understand a players streaks across a season, but by creating visualizations we can take our understanding to another level.
We’re going to use Matplotlib to build some plotting functions. Since the main focus of this tutorial is identifying and analyzing plots, we’re not going to go into detail about the matplotlib methods we use to construct our plots, but we encourage you to dive into the documentation if you’re curious!
Let’s get started by importing the library.
import matplotlib.pyplot as plt
# this cell is hidden from the post
%matplotlib inline
%config InlineBackend.figure_format='retina'
Plotting Streaks
We’ll start by creating a simple function that uses the pandas plotting function Series.plot.bar() to generate a visualization of the streaks. We’ll have our function take the raw shot data and we’ll use our generate_streak_info() function from earlier to process the streak data before we plot.
def plot_shots(shots):
"""
Calculate and plot streak data.
"""
streak = generate_streak_info(shots)
fig, ax = plt.subplots(figsize=(30,10))
streak['streak_counter'].plot.bar(ax=ax, color='black', width=1)
plt.show()
plot_shots(durant_ft)

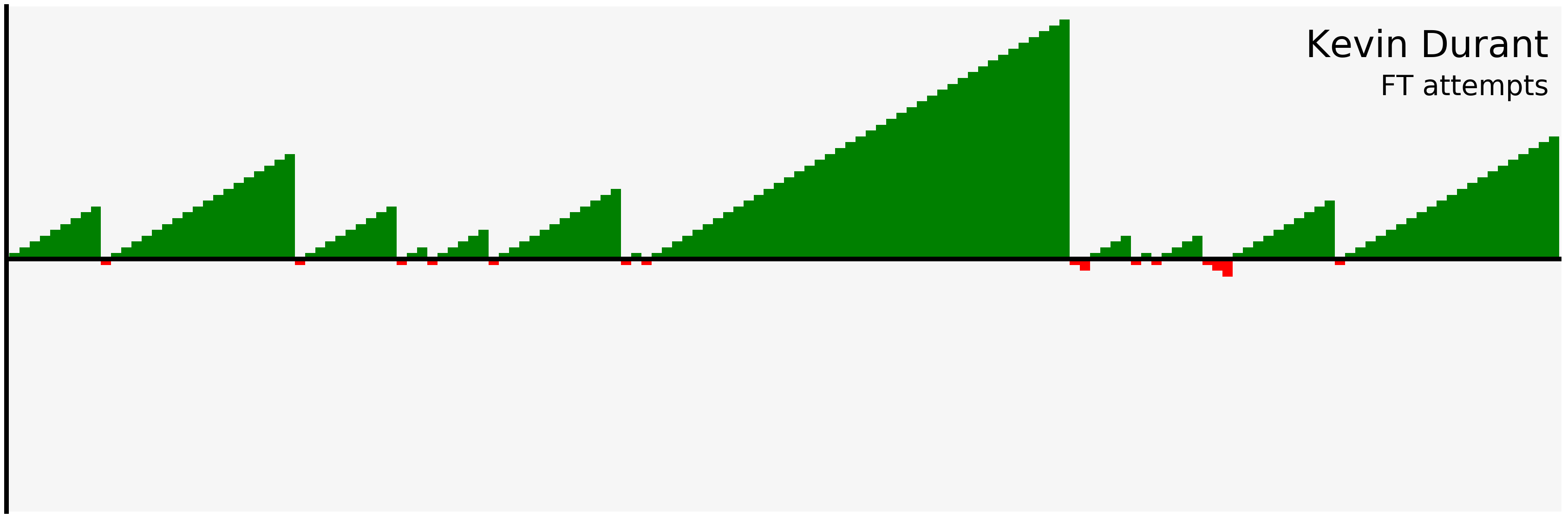
Immediately we can get a sense that there are several large streaks here, and that the largest streak is almost double the length of the next largest streak.
Differentiating Make and Miss Streaks
One shortcoming of our plot is that streaks of makes and streaks of misses appear the same.
Let’s create a new version where we filter makes and misses into two separate columns so we can plot them using separate colors. We’ll also multiply the misses by -1 so that they plot in the opposite direction.
def plot_shots(shots):
"""
Calculate and plot streak data.
"""
# filter data into makes and misses
streak = generate_streak_info(shots)
streak.loc[streak['result'] == "make", "makes"] = streak['streak_counter']
streak.loc[streak['result'] == "miss", "misses"] = -1 * streak['streak_counter']
# plot the streaks
fig, ax = plt.subplots(figsize=(30,10))
streak['makes'].plot.bar(ax=ax, color='green', width=1)
streak['misses'].plot.bar(ax=ax, color='red', width=1)
plt.show()
plot_shots(durant_ft)
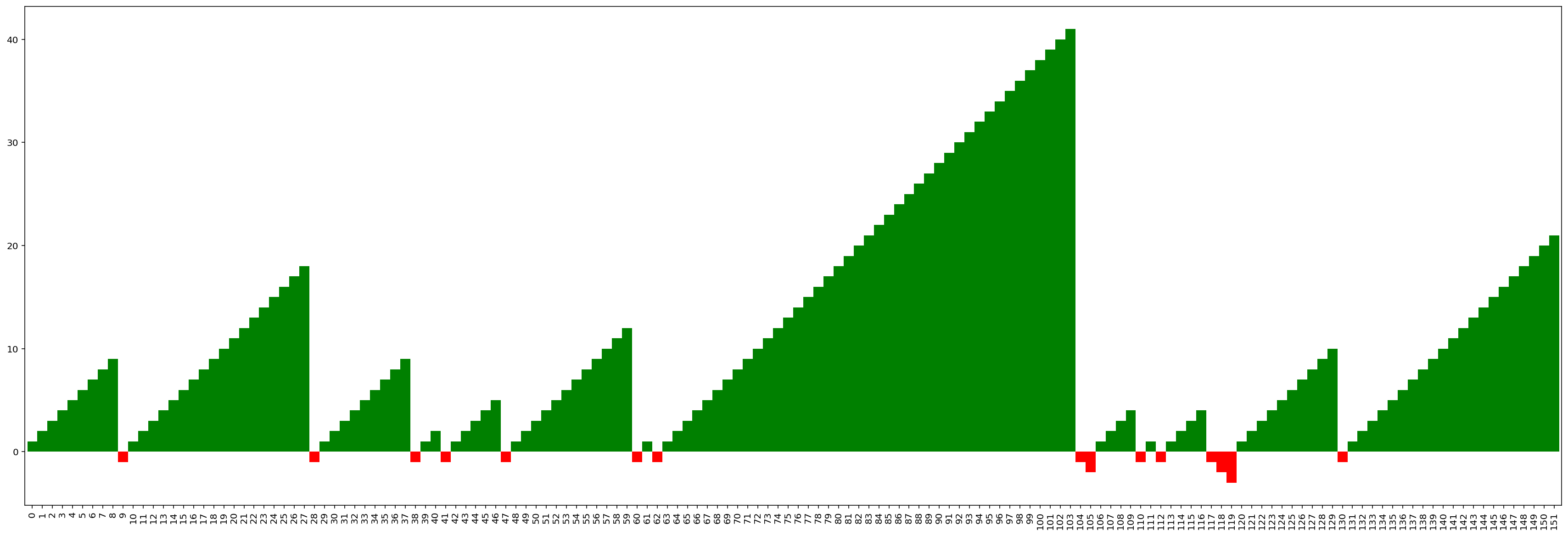
Now we’re really getting a sense of Durant’s shooting - he hardly misses free throws, and has lots of long streaks of makes.
Styling our Plots
Next, let’s clean up our plots a little. We’ll:
- Remove all but the left spine.
- Add a black axis line between the makes and misses.
- Make the right spine match the styling of the middle axis line.
Because it’s becoming more difficult to identify the new code in our function, we’ve left a big comment box so you can see where the new code starts:
def plot_shots(shots):
"""
Calculate and plot streak data.
"""
# filter data into makes and misses
streak = generate_streak_info(shots)
streak.loc[streak['result'] == "make", "makes"] = streak['streak_counter']
streak.loc[streak['result'] == "miss", "misses"] = -1 * streak['streak_counter']
# plot the streaks
fig, ax = plt.subplots(figsize=(30,10))
streak['makes'].plot.bar(ax=ax, color='green', width=1)
streak['misses'].plot.bar(ax=ax, color='red', width=1)
##################
# NEW CODE BELOW #
##################
# add a horizontal line at y=0
plt.axhline(y=0, color='black', linewidth=5)
# remove ticks from all sides
plt.tick_params(axis='both',
bottom=False,
labelbottom=False,
left=False,
labelleft=False)
# remove spine from top, bottom and right
ax.spines['top'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['right'].set_visible(False)
# set the left spine to a line width of 5
ax.spines['left'].set_lw(5)
plt.show()
Let’s plot not only Durant’s freethrows, but also Harden’s three point streaks, which we observed earlier:
plot_shots(durant_ft)
harden_3pt = filter_shots("James Harden", "3PT")
plot_shots(harden_3pt)
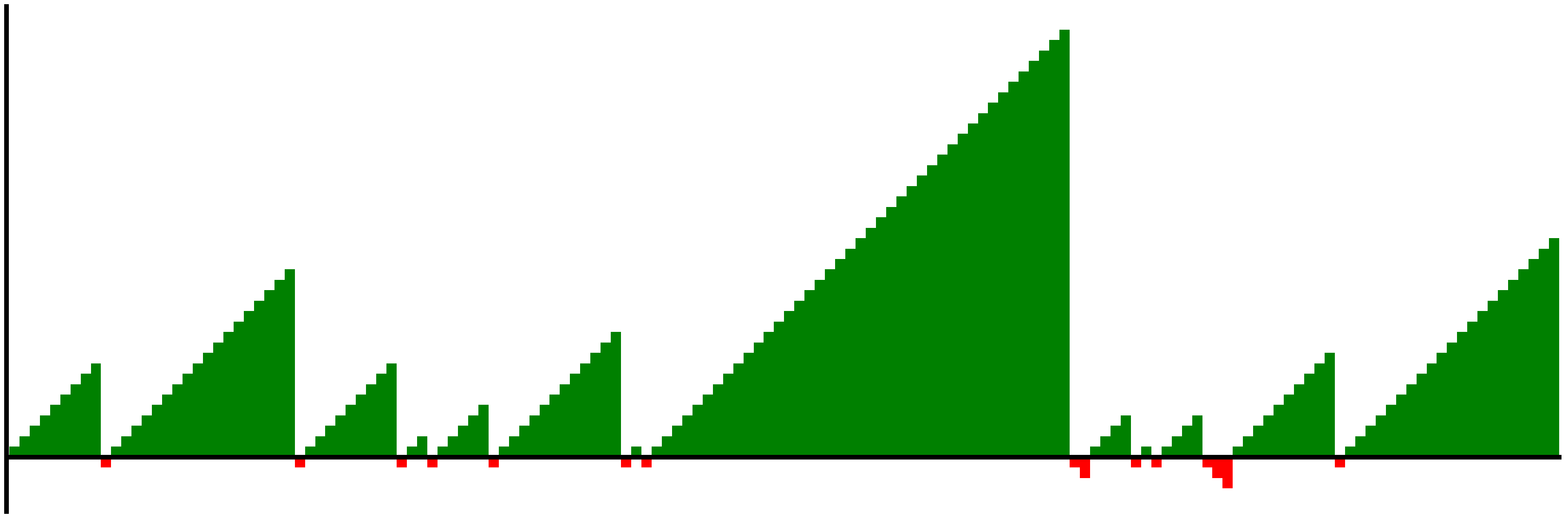
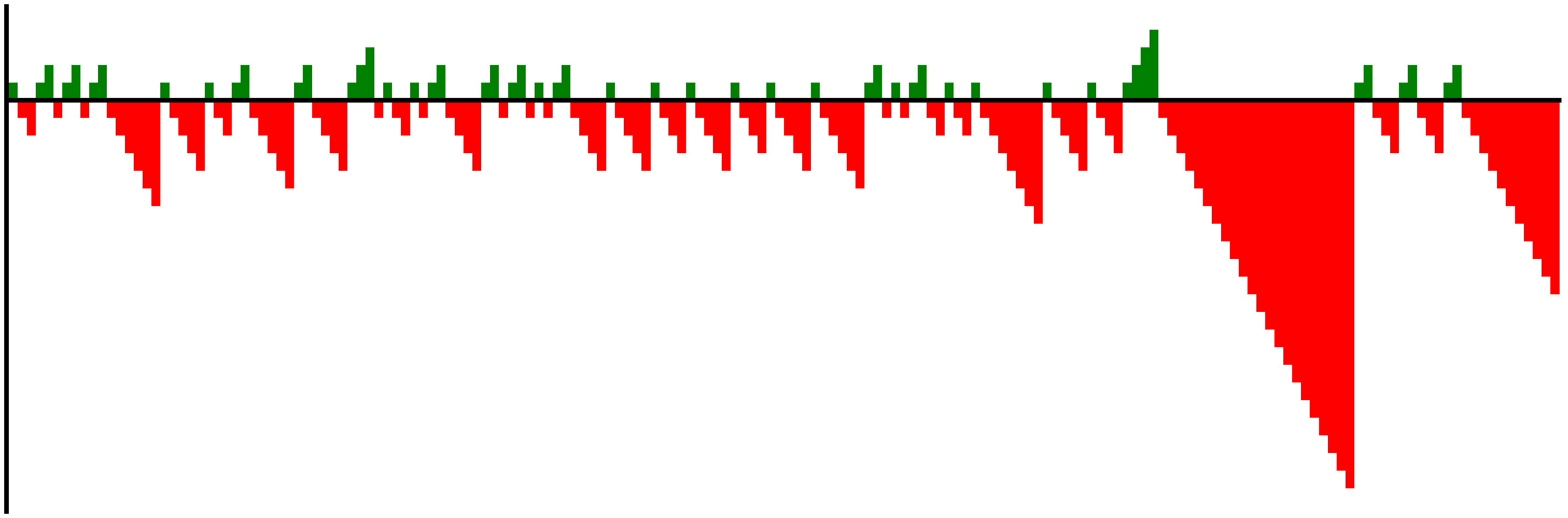
Making Symmetrical Plots
When we compare the two plots they look unbalanced because one favors the positive side and the other the negative side.
Let’s calculate the largest of the y limits for our plot and use it to make the limits symmetrical.
def plot_shots(shots):
"""
Calculate and plot streak data.
"""
# filter data into makes and misses
streak = generate_streak_info(shots)
streak.loc[streak['result'] == "make", "makes"] = streak['streak_counter']
streak.loc[streak['result'] == "miss", "misses"] = -1 * streak['streak_counter']
# plot the streaks
fig, ax = plt.subplots(figsize=(30,10))
streak['makes'].plot.bar(ax=ax, color='green', width=1)
streak['misses'].plot.bar(ax=ax, color='red', width=1)
# add a horizontal line at y=0
plt.axhline(y=0, color='black', linewidth=5)
# remove ticks from all sides
plt.tick_params(axis='both',
bottom=False,
labelbottom=False,
left=False,
labelleft=False)
# remove spine from top, bottom and right
ax.spines['top'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['right'].set_visible(False)
# make the left spine have a line width of 5
ax.spines['left'].set_lw(5)
##################
# NEW CODE BELOW #
##################
# calculate the largest of the y limits, and use that to
# set symmetrical limits
limit = np.abs(plt.ylim()).max()
plt.ylim(-1*limit,limit)
plt.show()
plot_shots(harden_3pt)
plot_shots(durant_ft)
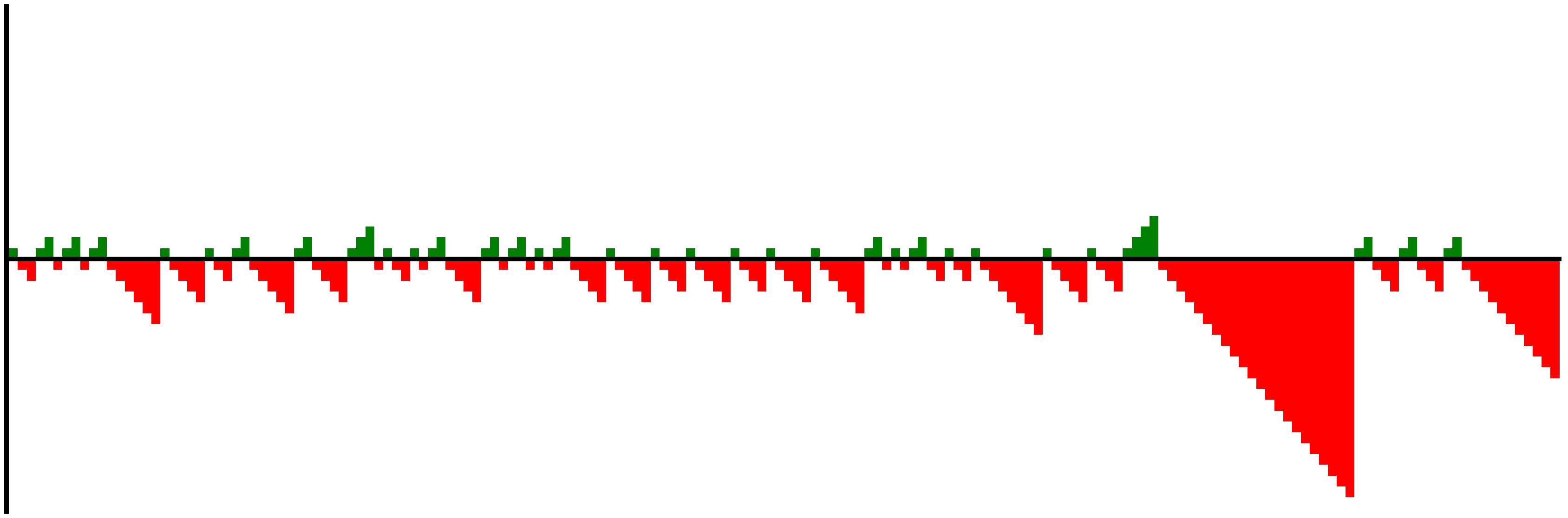
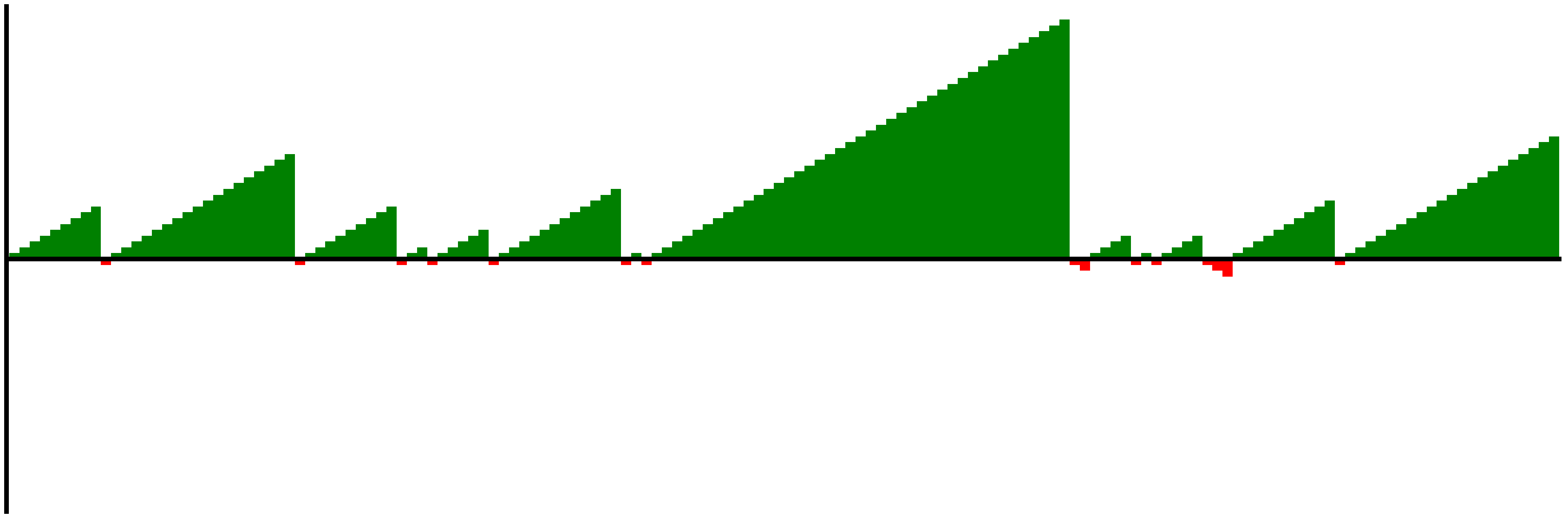
The difference between the two sets of data is much clearer visually now.
Adding background and titles
Finally, let’s add a shaded background to the plots and a title that annotates our data. We’ll need to add two arguments to our function with the player_name and shot_info:
def plot_shots(shots, player_name, shot_info):
"""
Calculate and plot streak data.
"""
# filter data into makes and misses
streak = generate_streak_info(shots)
streak.loc[streak['result'] == "make", "makes"] = streak['streak_counter']
streak.loc[streak['result'] == "miss", "misses"] = -1 * streak['streak_counter']
# plot the streaks
fig, ax = plt.subplots(figsize=(30,10))
streak['makes'].plot.bar(ax=ax, color='green', width=1)
streak['misses'].plot.bar(ax=ax, color='red', width=1)
# add a horizontal line at y=0
plt.axhline(y=0, color='black', linewidth=5)
# remove ticks from all sides
plt.tick_params(axis='both',
bottom=False,
labelbottom=False,
left=False,
labelleft=False)
# remove spine from top, bottom and right
ax.spines['top'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['right'].set_visible(False)
# make the left spine have a line width of 5
ax.spines['left'].set_lw(5)
# calculate the largest of the y limits, and use that to
# set symmetrical limits
limit = np.abs(plt.ylim()).max()
plt.ylim(-1*limit,limit)
##################
# NEW CODE BELOW #
##################
# add summary text
x = streak.shape[0] * 0.99
y1 = limit * 0.8
y2 = limit * 0.65
ax.text(x, y1, player_name, horizontalalignment='right', fontsize=40)
ax.text(x, y2, shot_info, horizontalalignment='right', fontsize=30)
# add background shading
rect_coords = (-.5, -1 * limit)
rect_width = streak.shape[0] + .5
rect_height = 2 * limit
bg = plt.Rectangle(rect_coords,
rect_width,
rect_height,
color='#f6f6f6',
zorder=-1)
ax.add_patch(bg)
plt.show()
plot_shots(durant_ft, "Kevin Durant", "FT attempts")
plot_shots(harden_3pt, "James Harden", "3PT attempts")
Visualizing Interesting Streaks
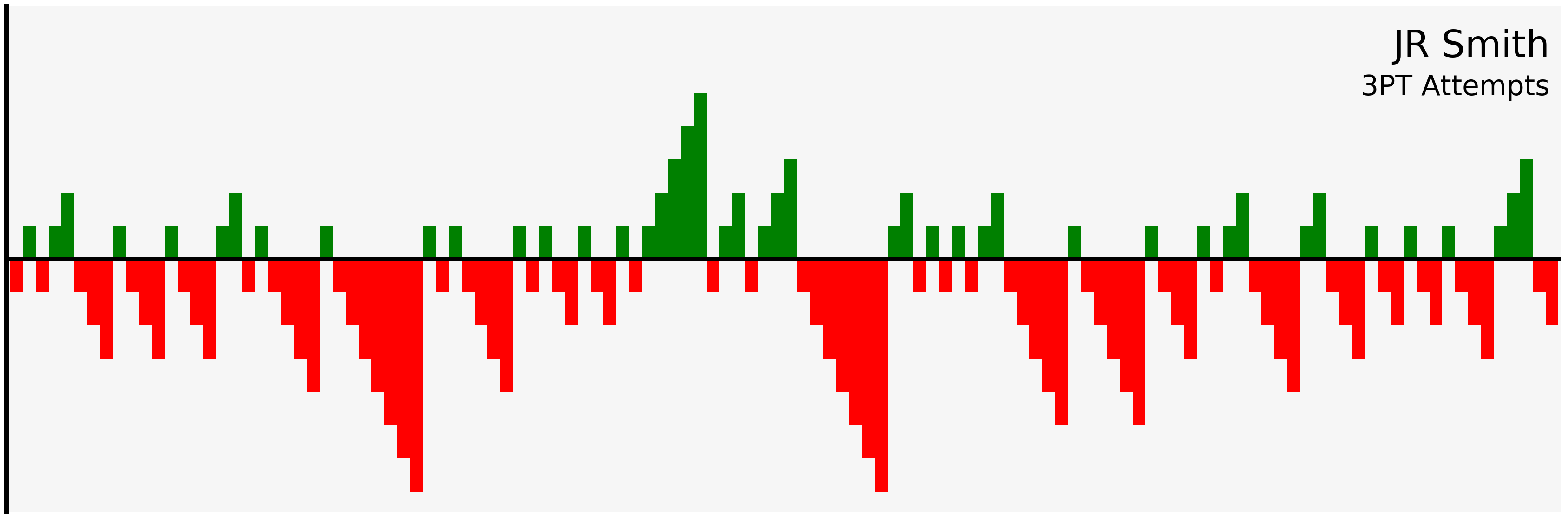
Let’s create a function that filters and plots all in one, and look at JR Smith’s three point streaks:
def filter_and_plot(name, shot_type):
"""
Filter by player and shot type and then plot
the resultant data.
"""
shots = filter_shots(name, shot_type)
label = f"{shot_type} Attempts"
plot_shots(shots, name, label)
filter_and_plot("JR Smith", "3PT")
And now let’s look at a few other interesting streak plots:
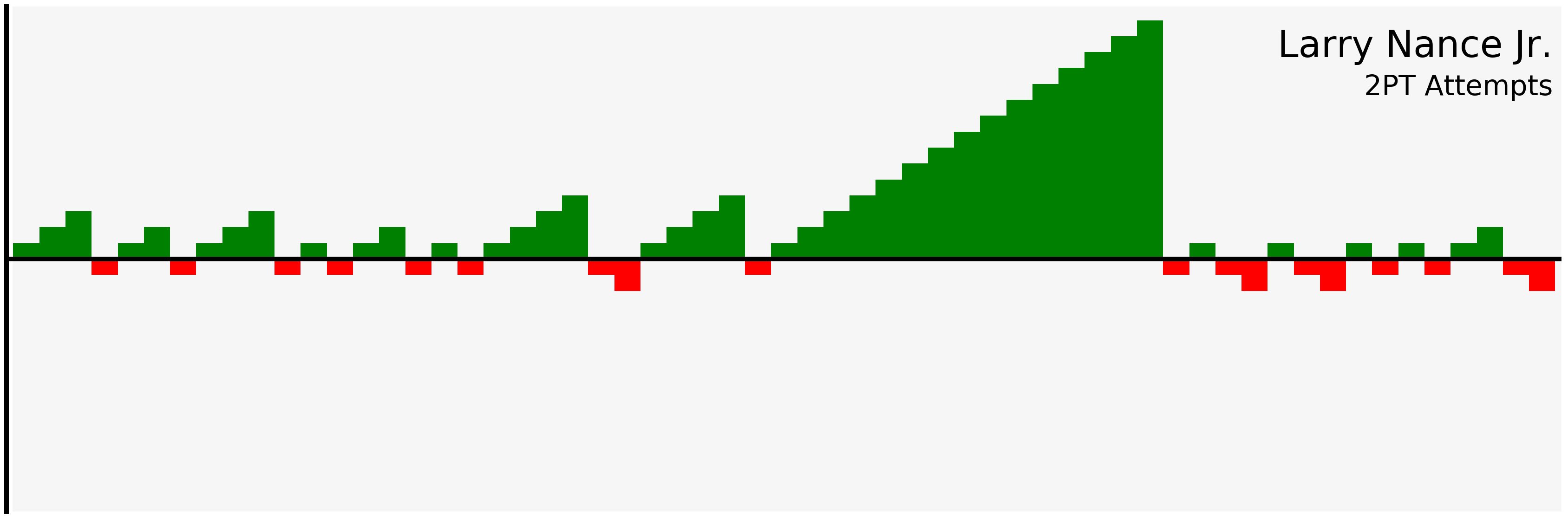
filter_and_plot("Larry Nance Jr.", "2PT")
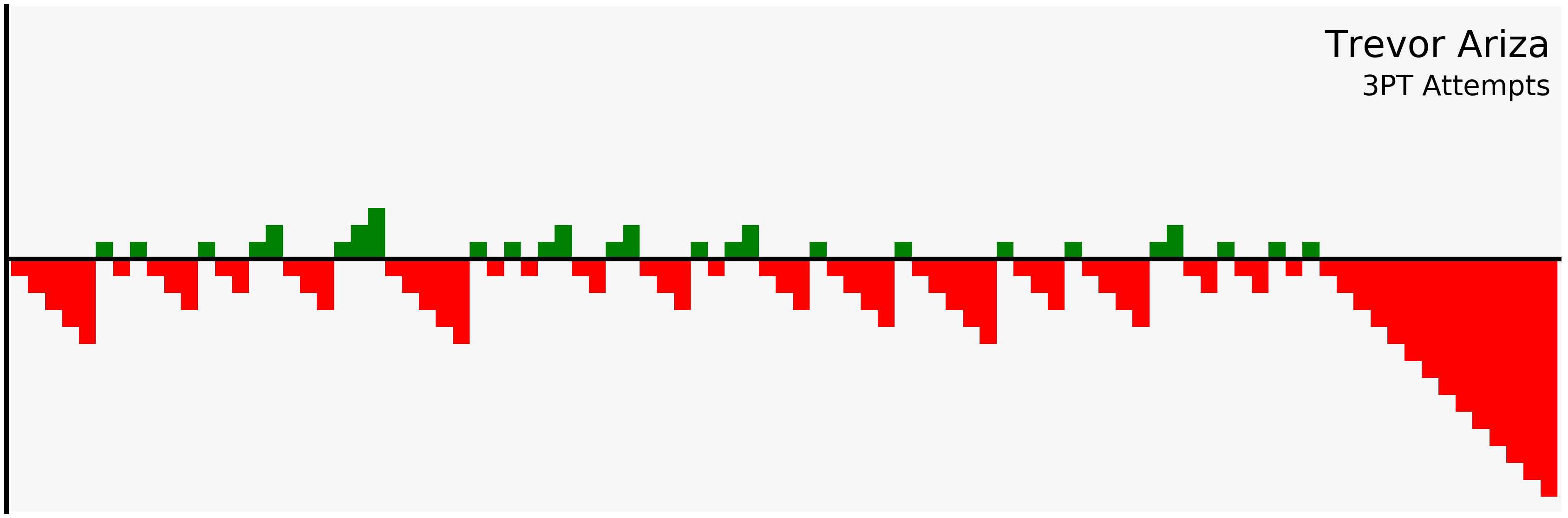
filter_and_plot("Trevor Ariza", "3PT")
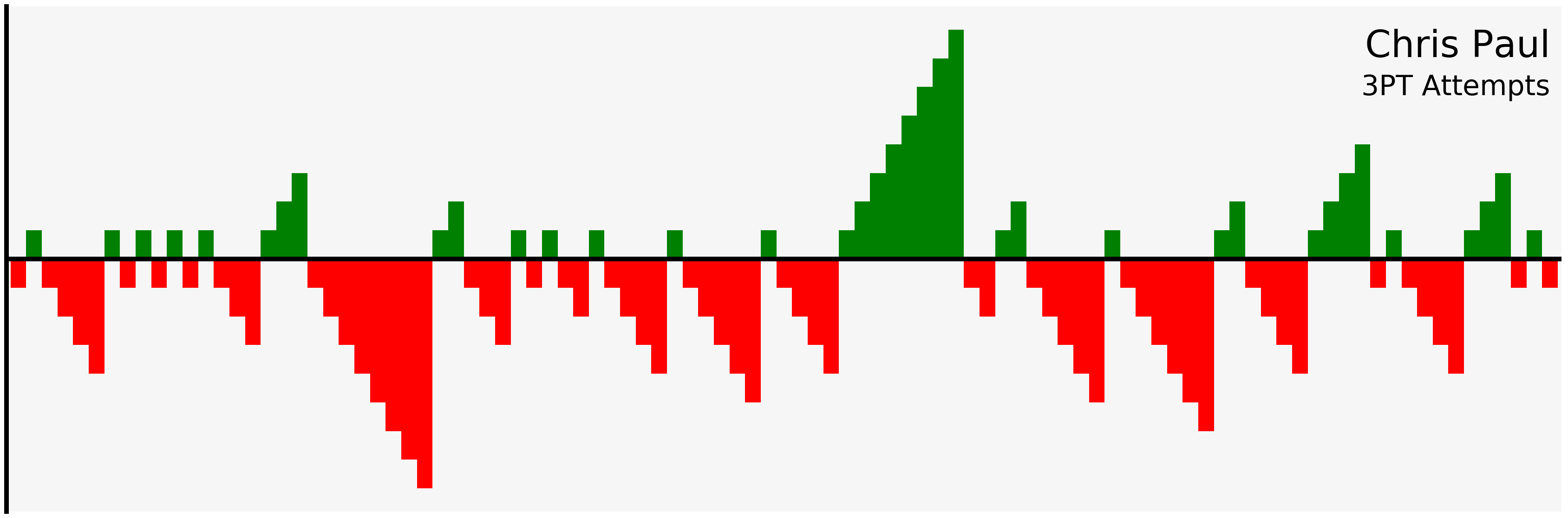
filter_and_plot("Chris Paul", "3PT")
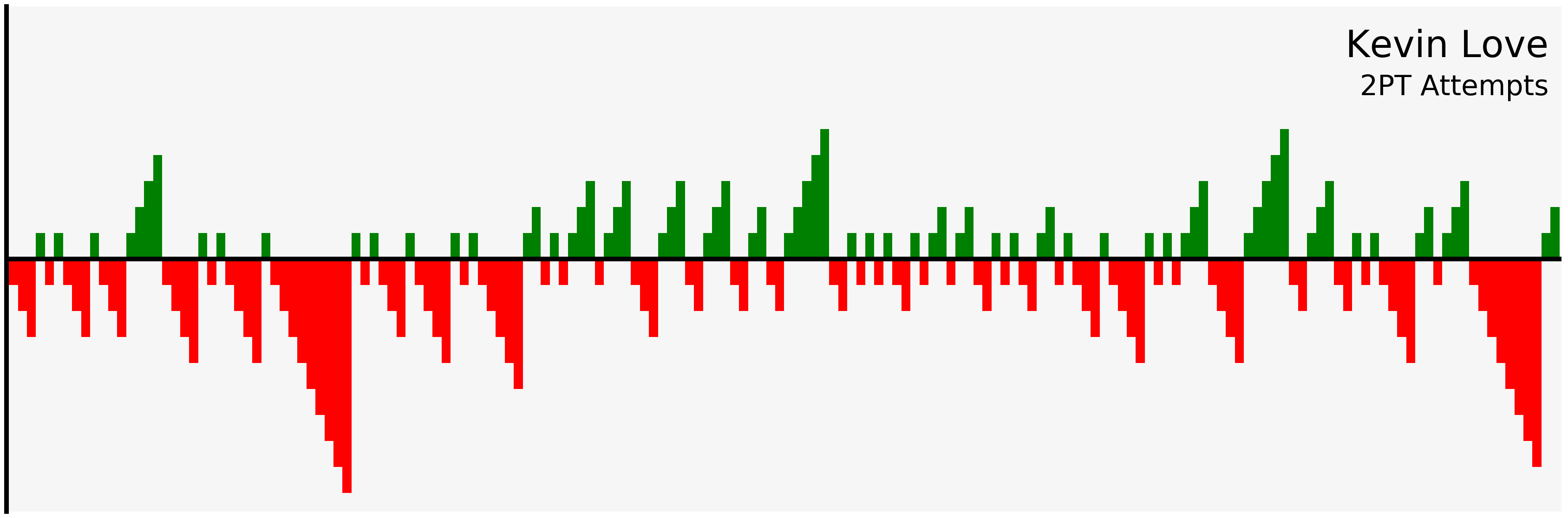
filter_and_plot("Kevin Love", "2PT")
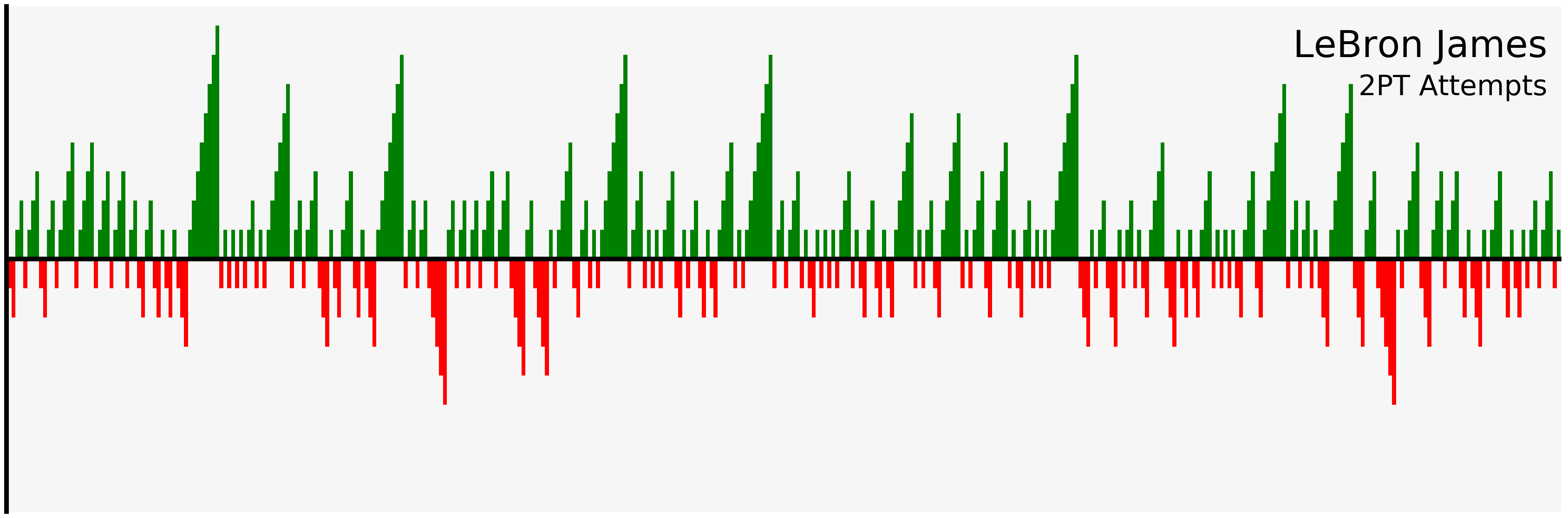
filter_and_plot("LeBron James", "2PT")
Next Steps
In this tutorial, we learned how to calculate streaks using pandas, summarize streak data and visualize streaks using Matplotlib.
If you’d like a challenge, you might like to extend this tutorial by:
- Adding extra text to the plots, eg team and shooting percentage.
- Adding annotations that show the peaks of the largest streaks.
- Calculate streaks for whole teams.
- Calculate team runs (streak of scores without other team scoring).
The original version of this post had an error in the logic that calculated streaks for all players and shot types. Thankyou to Cristina Guzman for drawing my attention to this issue.